Cronlocker - Distributing Cronjobs Across Hosts

One of the goals in operating any IT system is to make it available 100% of the time.
Having the best of the best of the best hardware to ensure reliability is not good enough, because every piece of hardware is limited in the amount of data it can handle.
At some point it is therefore necessary to scale the system horizontally by adding more hosts with the same code deployed to allow handling more load. This approach works really well for request based systems where the system only has to do work in response to being triggered from another source.
An example for this is a simple HTTP host which listens and waits for a request to arrive. The more hardware, the more of such requests can be handled. If any of the hosts goes down, there are enough others to fill in for it. Scaling a system like this works quite well (ignoring any issues that may arise from a database not being able to handle the load).
Regular Time Triggered Tasks
Next to this request-based kind of work, there is also work that has to be executed within a certain time period. The easiest way to achieve regular time based execution is usually cron, which can be found or easily installed for most operating systems (Note: it may be called something else on non-unix systems). The simplicity and reliability of cron, as well as our familiarity with it was the reason we decided to use cron for code that has to be executed automatically on a regular basis. This can be daily at a certain time, monthly or even every minute.
Unfortunately cron is not built for distributed systems where each application runs on countless hosts. Cron is built to run on a single host and to execute a defined program at the time when the configured pattern matches. Therefore we started out with selecting a single host which would handle the cronjob execution.
This worked great 99% of the time. In rare occassions this host may not be able to execute the cronjobs for a while. Such occassions can include a host going down unexpectedly as well as for maintenance reasons. For important tasks this is simply not acceptable. Same as for request based applications a possible solution is to simply run the cronjobs on more than one host.
In many places our cronjobs were written in a way that assumed that the code is only running once at the same time. Rewriting the code in such a manner that it can handle being executed more than once is one option to solve this problem. In many cases that is easier said than done. Ensuring that code is run at most once at the same time can be achieved in easier ways, especially if one wants to avoid having to solve it for every cronjob individually.
We looked around a bit and came across systems like dkron, chronos, and rundeck.
Neither of those solutions suited us very well in terms of setup required for our existing system and for adding the additional costs of maintaining it.
Idea: Utilizing Consul
Fortunately we previously added consul to our system. The short term goal was to manage the configuration state for our database cluster. The long term goal was to store configuration state for our other software. For this additional usecase consul also provided a feature that is a perfect fit: Locks. Consul locks allow to retrieve a key and to lock it so that noone else may receive a lock for it in the meantime. Consul will ensure that this is propagated through the cluster and to enforce that other instances of a cronjob will not receive the same lock.
Adding this as code for every single cronjob would have been a lot of work though. In the best case a cronjob should not care where it is executed. It also shouldn't have to worry about other instances of itself running on another host.
Therefore we developed cronlocker. The purpose of cronlocker is to wrap an existing command and to try to get a lock on the configured key from consul. If the lock can be obtained, cronlocker will execute the command. If the lock cannot be obtained, cronlocker will simply stop there and leave it be.
After implementing cronlocker we only had to wrap it around all our cronjob commands without any need to adjust the actual logic for this.
Wrapping these could be easily done as follows:
# usage: cronlocker -key=<consul key> <command>
# command before wrapping:
bundle exec rake general:generate_invoices
# command after wrapping:
cronlocker -key=lock/invoicing/general_generate_invoices bundle exec rake general:generate_invoices
More detailed usage information can be found in the github repo: https://github.com/Barzahlen/cronlocker
Deployment
We started deploying cronlocker by adding it on one host for a few selected cronjobs. After seeing that this did not cause any issues and the cronjobs still ran as well as they did before, we started rolling out cronjobs on multiple hosts. At first on two additional ones. The result was visible soon afterwards: we did not only receive log data for the cronjobs on a single host but rather saw it distribute across multiple hosts.
This can be seen in the following picture, where the three different colors represent the hosts on which a particular cronjob was executed over time.
At first it only ran on a single host. Later it only runs on the original host some of the time.
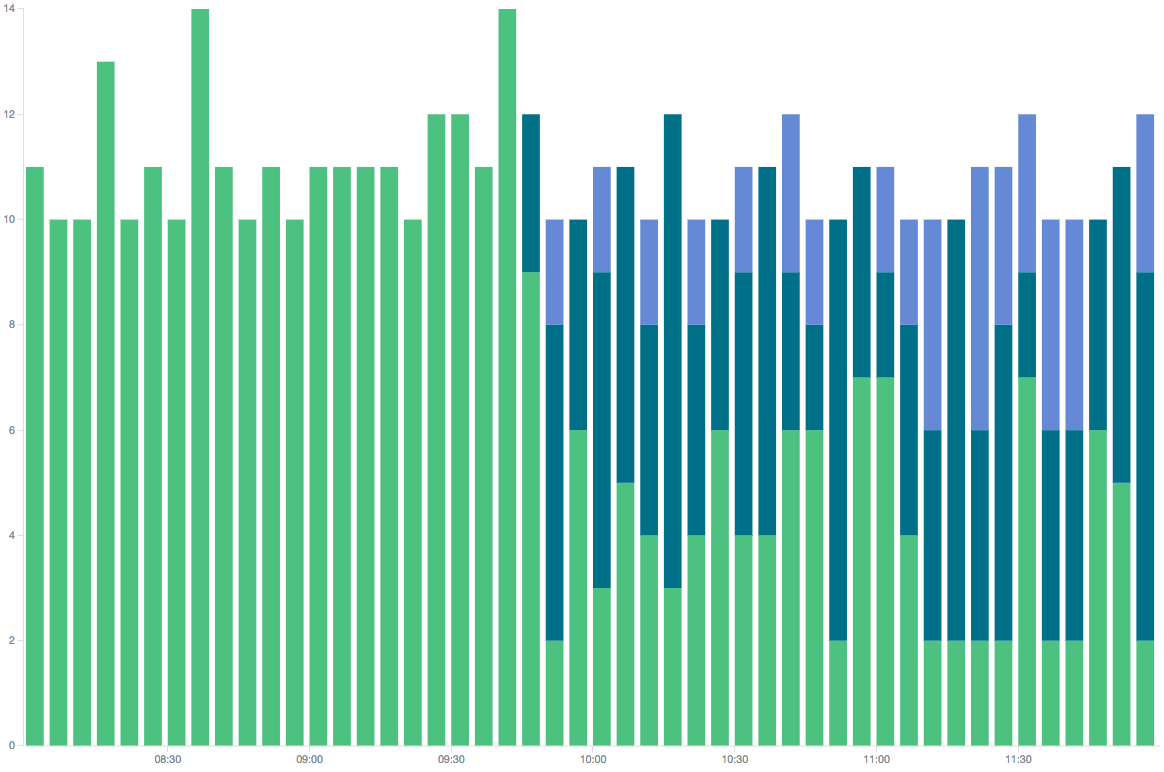 cron execution redistribution after deploying cronlocker. Different colors represent different hosts
cron execution redistribution after deploying cronlocker. Different colors represent different hosts
Conclusion
cronlocker is a very simple tool with an easy setup (if you do not count consul) which can be used with any type of task that might be executed by cron.
It helped us run cronjobs on multiple hosts without having to adjust each of them indiviually to ensure that not more than one instance of it may run at once. We can now take down and re-deploy hosts much easier without having to do as much preparation beforehand for regular running tasks.
One thing that remains to be solved is ensuring that a task was successfully executed and did not fail mid execution after having acquired the lock.