Paginating things in different ways


Years ago, when we started migrating our Rails monolith into Rails and Sinatra micro services, one of the things we messed up was not enforcing defaults and maximum values. In hindsight of course that was pretty stupid and could have been avoided, but at the time it cost us 2 nights of deployments until we realized what was going on. We did not have automated zero downtime deployments properly figured out back then so our deployments were scheduled for the night. To finish the anecdote: a dashboard was accessing data from a micro service but did not send any page information which resulted in the service trying to return everything in one response - because we did not enforce a default limit on the page size. This took down the system. We were fortunately deploying at night so that it had minimal impact. It took us some time to figure out which change for that weeks deployment broke things.
We knew that pagination was important - we had followed a book for the basic structure of our micro services after all. We just did not get it right the first time. After a recent discussion with some other architects about their approach to pagination, I got reminded that my (by now) default approach to pagination may not be the same as other people's and it also highly depends on what tools you started out with that formed your preference.
Why paginate anyway?
Pagination serves the purpose of splitting a result set into multiple smaller parts. This is similar to how a book may be more convenient to navigate than a scroll or the output of a dot-matrix printer. Depending on the use case, it may be less convenient. Either way, in a distributed system the client has some constraint of how much data makes sense to process at once, the server does as well.
In web applications you can often observe that the first 10 or so entries are displayed and then you can ask for the next page. A prime example of this is the search result of pretty much every search engine. Another with a different mode of going from one page to the next are the repositories that a user has starred on Github.
So we paginate to ensure that loading the data does not overwhelm the client or server component. That applies between micro services as well as for the user consumption in e.g. a browser or for endlessly scrolling on social media apps.
Page-per_page approach
When we started out, we simply went for the approach of page and per_page. This was simple for us, because the libraries for pagination in Ruby (that we knew about) exposed their parameters in the same way. Those libraries are will_paginate and kaminari.
# Example query string
?page=1&per_page=10
The advantage of this approach is that it works well with how we tend to display information in the UI: pages of limited length (per_page) that can be addressed by a page number. It allows to jump to a specific page while skipping over multiple pages when you are confident it is not on that page. It also allows to just go through the result set page by page. Additionally, if a user has a rough idea how many pages there are, it is possible to request some pages in parallel to speed up going through them. A place where this sort of pagination is visible is the Gitlab REST API.
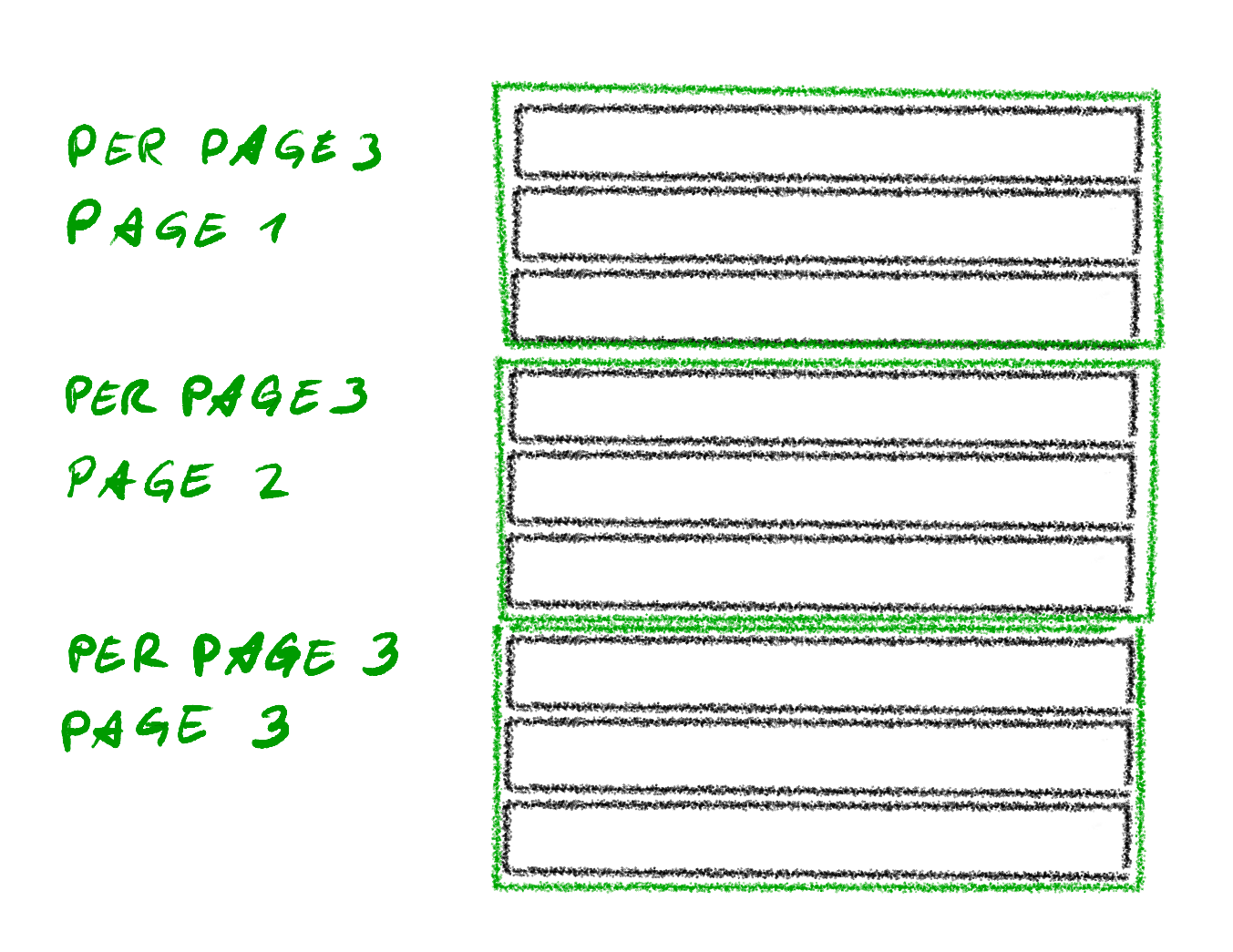
The approach also translates easily into LIMIT and OFFSET for a SQL query while not having every client implement the math again for calculating the LIMIT and OFFSET values for the next page. Other database types often have something similar.
One general downside when using LIMIT and OFFSET on a SQL query is, that for increasing OFFSET the queries will get slower. In order to know which 50 entries need to be displayed after the first 5000, the database has to calculate the first 5000 also. And 5050 for the next page.
It is also not necessarily straight forward to change the per_page value half way through, as it affects the whole sequence of pages.
Another downside of this approach is that it brings up the discussion about whether it should start counting with page 0 as the first page. Given that end users are used to page 1, I would go for starting the count at 1 in this case. And sticking to a zero based count for other things.
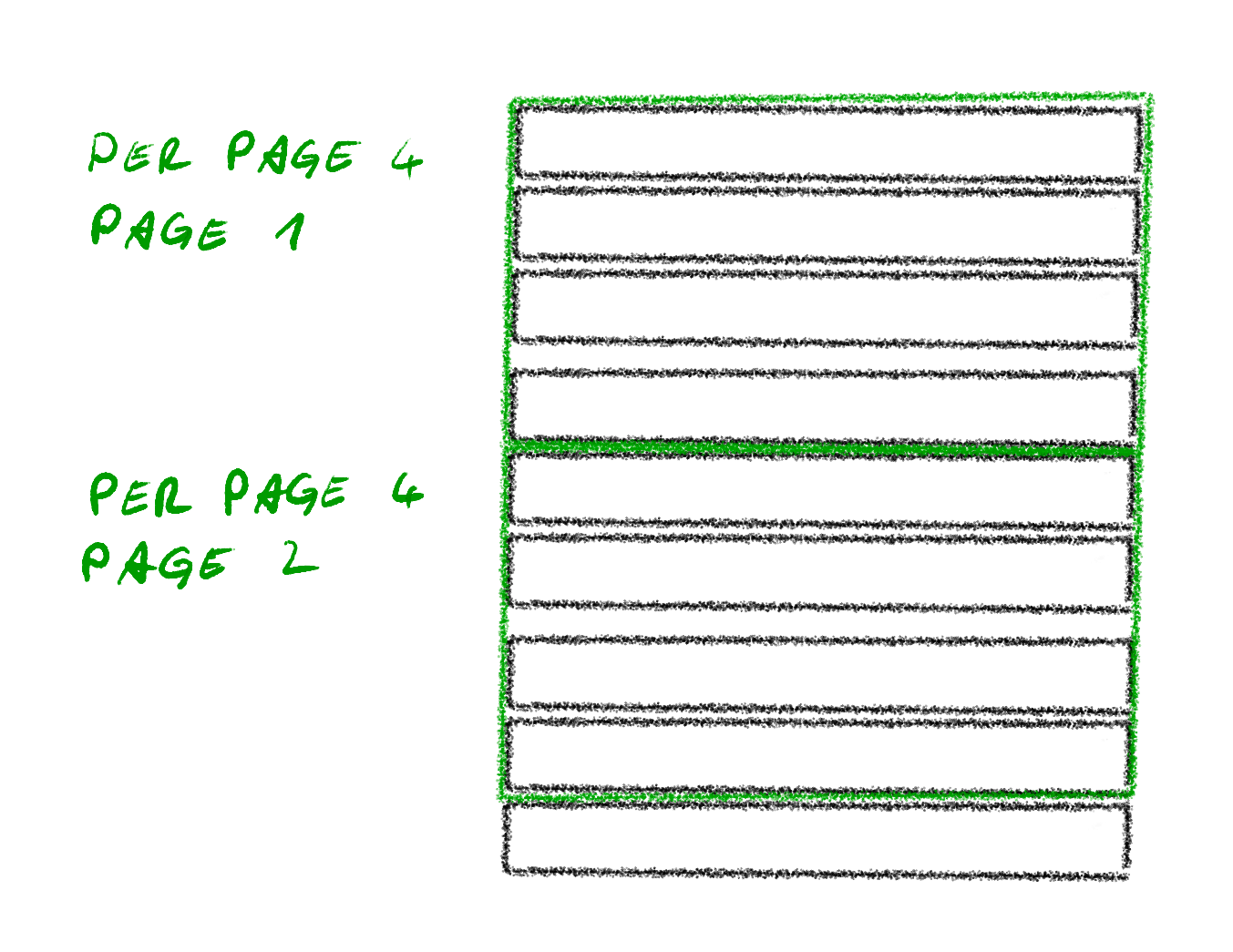
Limit-offset approach
The limit and offset approach is very similar to page and per_page. It actually allows for more precise retrieval of the entries. Where the page-per_page approach only allows retrieving a multiple of per_page as the specific page, the limit-offset approach allows to get 14 entries after the first 17. In the last 10+ years I never needed that. Usually, I just needed the next page and I could not make assumptions about where exactly the entries that were needed would be in the result set. So going through the results page by page or displaying an individual page were covered.
# Example query string
?offset=0&limit=100
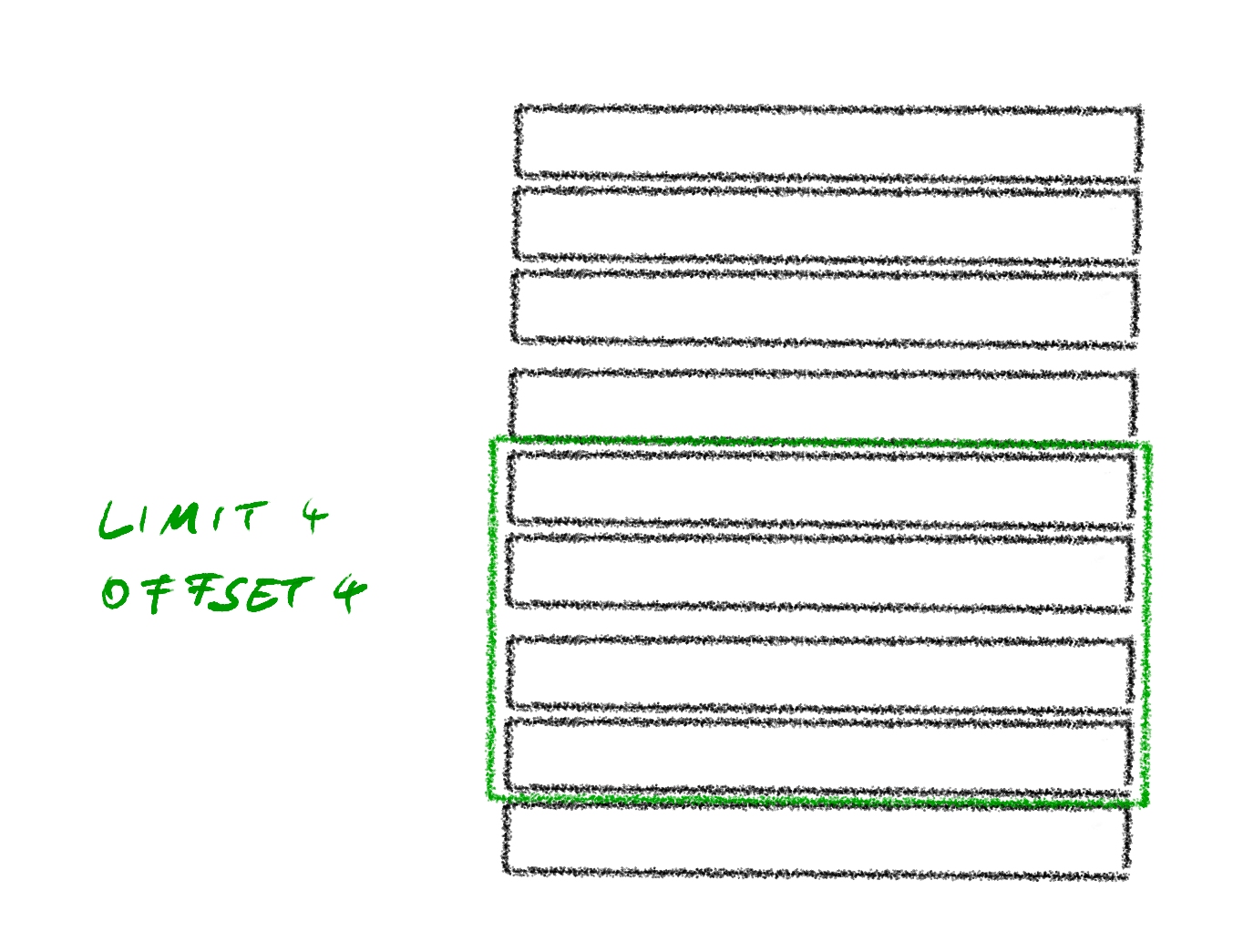
Aside from being more flexible, it also is just simpler on the server side. It allows for simply implementing limitations on what sort of values can be passed on the server side and otherwise it can be passed more of less straight into the database query. On the client side it might result in more work though, especially if the flexibility shall not be exposed to the end user directly.
Another advantage of page-per_page and limit-offset is that it works with every kind of sorting on the result set and any sorting.
Same as the page-per_page approach, it gets slower the higher the page number. This is often acceptable for the regular UI use case and the anecdotal evidence of people rarely going to page 2 of the Google search results showcases the point that high page numbers / large offsets are often not needed.
Cursor-based approach
For the export case with very high numbers of entries we want to avoid that it gets slow after a while, potentially causing timeouts between the client and server. We also want to ensure consistency in the result. When going through multiple pages it can be likely that a new entry is created and changes what it means to be on page 2, resulting in missing and duplicated values. This is bad for CSV files generated from exports.
# Example with human readable cursor
?limit=10&after=id:17
# Example with obfuscated cursor
?after=Y3Vyc29yOnYyOmlkOjI3
One option for that is the cursor-based approach. The cursor-based approach allows passing the lower/upper limit of a specific value and basically asking for the N entries after that value. For example, on page 1 the last entry has id 28. On the next page it is possible to ask for 20 entries with a value higher than id 28. This requires the result set to be sorted by the column used for the cursor though, as it would otherwise introduce a lot of ambiguity of what the server may return. When the entries are sorted by name, the highest id on the page might be 47, we may not have covered all entries up to 47 though and it might not be the last entry on the page.
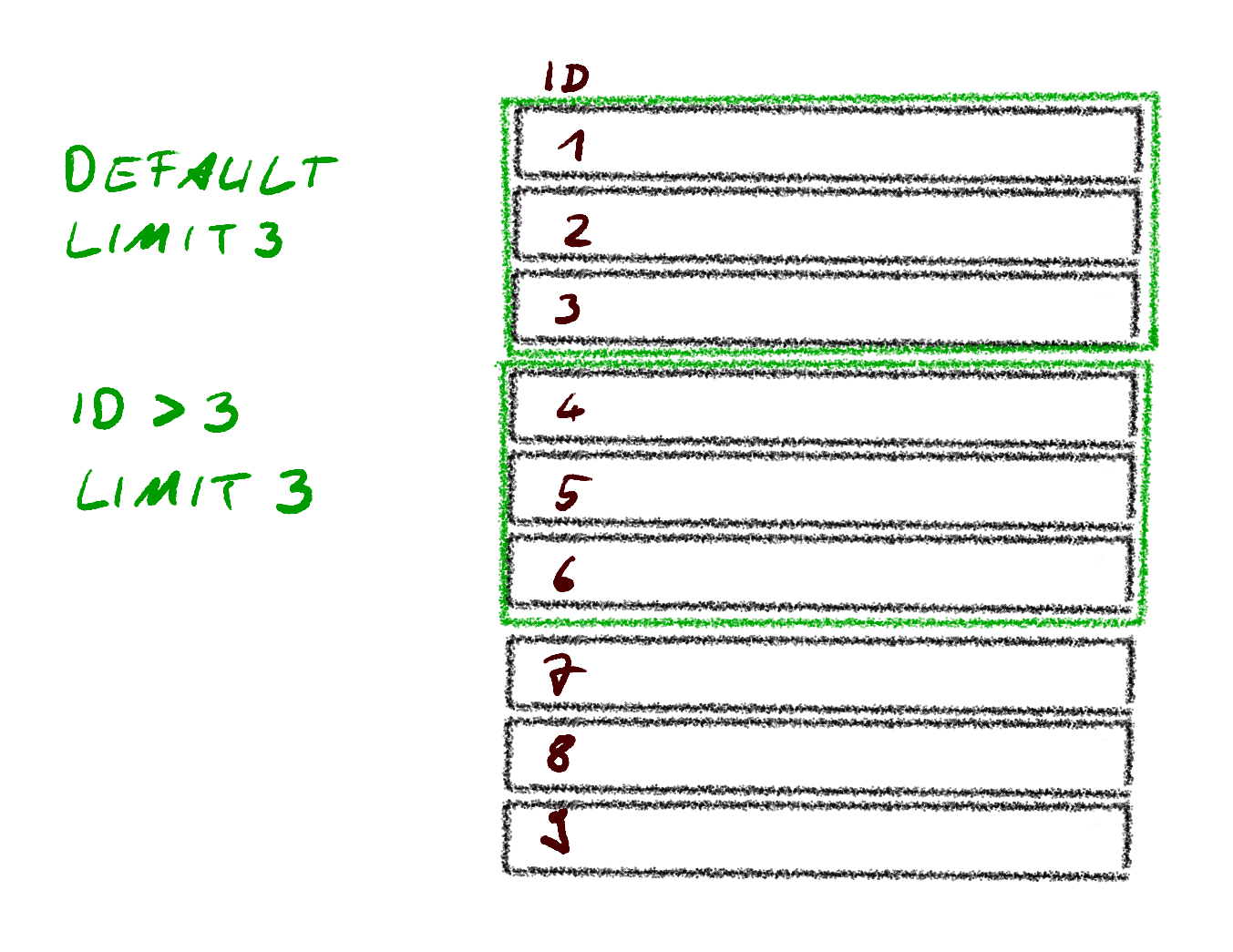
This approach does come closer to how we might go through a database query result if we can directly connect to the database, while avoiding that all entries will be loaded into memory at once.
In many cases the exact details for the next page are not directly exposed in the UI and instead might be obfuscated. For example getting the next page on the starred Github repositories does not directly reveal the value to the average user. It therefore limits the capabilities given to the user in the UI and it prevents the user from jumping to the 500th page without going through the first 499 pages.
Streaming approach
In a context where it is feasible to have a connection that is active for longer a streaming approach is possible. The classic example for this is the direct connection to the database and having a cursor for the executed query. That would allow us to grab the next entry once we finished processing the previous entry.
In a micro service world, where only the service itself should directly connect to the database, a possibility to solve this would be to open up e.g. a websocket connection. With the persisting connection we would not have to fear that our next request for the next page ends up at a different instance of the service and it could also just keep the DB query cursor open on the server side.
There are other ways of streaming the data than just websockets, but the general process is the same. It does add some complexity around keeping the connection open and potentially reopening it if the connection was lost.
What is the right approach?
As so often, the answer is it depends. It depends on your use case. I tend to stick with the page-per_page approach as a good default that given my personal experience is working well, despite its drawbacks. It provides a good basis and ticks all of the boxes for usually getting a few pages for a result set. The limit-offset approach is to a large degree a different naming for the same approach under the hood. Between those two in my opinion it comes down to preference most of the time. In some cases there may be a good reason to pick one over the other, e.g. when the flexibility of the limit-offset approach is actually needed to be accessible to the client. For us, displaying things in the UI tipped the scale to page-per_page.
For exporting data I have also implemented a cursor-based approach before, specifically to solve the issue with the slow queries with high offsets. It works really well there. As long as the result is sorted in a way that no new entries may be added in the middle and move pages, it also solves the duplication/missed entries issue. From that perspective I am very happy with the result and would use it for that case again.
So far I have avoided the streaming approach for this, as I did not want to have to keep the state on the server side about which page is or entry is next.