RabbitMQ Cluster Migration


In 2014 we introduced RabbitMQ in our production system as a means of doing asynchronous/background processing in our system. We needed to replace a functionality that we were handling with DelayedJob in our monolith.
For our growing service-based infrastructure, this was not the best fit though, as we wanted to eventually be programming language independent and we wanted something that was a bit easier to maintain.
We set out to evaluate different solutions. Eventually we settled on RabbitMQ because it supported sufficient throughput, could be operated without much effort, and supported all our use cases with sufficient assurance of delivery.
Since then, we have been operating our RabbitMQ cluster without any issues.
It was so effortless, that we did not even really need to keep it updated.
Therefore we were still running a now somewhat dated version of RabbitMQ with unencrypted connections. This might not necessarily be an issue in an environment that should not be accessible anywhere else, however in order to improve our internal system, we wanted to have that anyway.
We decided that we wanted to have a newer version and that features, such as connection encryption, should also be used now.
In order to not interfere with our existing system, both the RabbitMQ Cluster, as well as our services, we decided to "just" setup a new cluster and then migrate everything over to the new cluster.
Once the cluster was setup we needed a strategy to migrate all the workload over.
RabbitMQ Concepts Quick Intro
In order to better understand the process of migrating and its restrictions, a few concepts need to be clarified first.
A message is any piece of information that is sent through the cluster.
A RabbitMQ cluster interacts with producers, who connect to the cluster, produce messages and publish them. This can be any kind of program really. We usually think of it as an event that occurred, for which follow up actions may or may not happen.
The message is published by the producer, which means that it is handed over to an exchange. The responsibility of the exchange is to ensure that the messages go where they are intended to be going.
There are different types of exchanges which define how the messages are passed along, but this text will not go into them, as it is not really relevant for the cluster migration.
A queue is as the name describes a queue, in which messages sit and wait until they are consumed, or potentially expire. For us, the queue usually defines a specific action that needs to be taken.
The binding is the connection between an exchange and a queue, which defines, based on the exchange type, which messages are sent to which queues.
A message is published with some parameters, such as a routing key, which is the indication to the exchange how the message needs to be forwarded into a queue. It therefore decides which events result in which actions to be taken.
If no corresponding binding exists, nothing will happen.
Once messages sit in a queue, they are processed (or consumed) by a consumer. This consumer will then take the first message from the queue, handle it and acknowledge to the server that everything has been processed so that the server can forget about the message.
If something went wrong, the message would be added to the end of the queue again and wait to be processed again.
More information on this can be found on the RabbitMQ homepage, which has a great tutorial section.
Migration restrictions
In order to migrate from one cluster to the other, we needed to make sure that the queues, exchanges, and bindings exist before we publish messages.
One way to migrate this would have been to go through each queue, exchange, and binding in order to setup each of them beforehand mirroring the old cluster.
The usual behaviour with RabbitMQ is that it will be created the first time it is needed and if different parameters are provided for the entity with the same name, an error will be returned.
That way you can be sure that you have an entity that matches the specifications and it is not changed half way through its lifetime.
Generally it is recommended to define the bindings together with the queue. That way, everything will be setup, as soon as there are consumers available and one does not run into full queues with thousands of messages to be processed the first time a consumer is running. That in turn means that messages are dropped if there is no queue matching any kind of binding.
This set the restriction that we need to deploy the consumer side first.
Not every single one of our services has a clear consumer or producer side though.
We have services that are both consumers and producers in the same operating system process, and some which are only consumers or producers.
Another restriction was that we did not want to lose any message currently in the cluster or about to be published. Additionally it should not take much longer than usual for all those messages to be processed.
Since we set the cluster up to run on a different domain name in our system, we did not really need to think about having to turn off the old cluster and then start the new cluster. The migration of an individual application could be done by updating the RabbitMQ connection configuration.
Defining the migration order
With those restrictions and about 20 - 30 services which were using RabbitMQ at the time we needed to come up with a deployment order.
Fortunately with that many services it was still possible to go through each of them and check which other service would depend on the information from them. Additionally, we have each of the relevant applications running on more than one instance at a time and can deploy them in stages.
We made a list of all the services affected by this migration and which other application would be affected by this.
A way to create a dependency graph which resolves this could be a directed acyclical graph.
If there are no cycles in the graph, then, given a specific order, everything can be deployed without issues.
If there were cycles in there, we would have had to fall back to mirroring all exchanges, queues, and bindings.
While a single application sometimes uses RabbitMQ to manage asynchronous processing, with our level of throughput, this would generally not create an issue, as the consumers should all be there when a single message had been published.
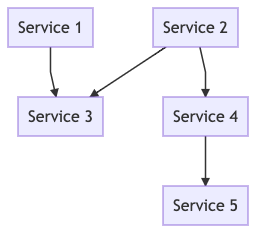
So we created a graph from our services. By disregarding cycles inside of a single application (one unit of deployment), we managed to come up with an acyclical graph. With this we could create the deployment order, where consumers would point to producers and any application without a dependency could be deployed without issues.
Executing the migration
Since no message should get lost or take too long to be processed, we could only migrate a part of it to the new cluster. We decided to go by roughly half, partly because it made sense to have enough capacity remaining on the old and already enough capacity on the new, and partly because that is how our deployment was split up anyway.
Therefore we first started to deploy one half of the instances of services with only consumers. Any messages still being published on the old cluster would then be consumed by the remaining instances. The queues, bindings and exchanges are already created on the new cluster.

This made us ready to deploy services with producer capability, assuming that all the corresponding consumers were already running with half their capacity.
This enabled us to already process messages published onto the new cluster without losing any messages.
We then went through the list of migrations by building up and tearing down a stack: For the first half we metaphorically speaking, add an element onto the stack, for the second half we would then take the element of the stack and deploy that service.
This allowed us to not publish messages onto the old cluster anymore, while still having the remaining messages consumed.
Stray/left-over messages
Once everything was migrated, we still had a few messages left in the queues, because we are utilizing dead-letter exchanges for delaying repeated processing.
For these messages, which might sit there for a few hours in some instances, we wrote a migration script. This script checked each of the queues on the new cluster and check if there are messages on the old cluster.
Any queue on the new cluster must also be on the old cluster, so this was an additional check that we had not forgotten anything that is actually used. The old cluster might still have queues that we were no longer using and forgot to clean up though.
The script would then consume the messages from the old and publish them to the new cluster, including all of its properties.
The only thing we could not really migrate was how long a message might have already been waiting inside of a delay queue. So if there was a timeout on the queue, this would result in a restart on the new cluster.
Fortunately for us, this was not an issue, because all affected messages were in a sort of busy waiting state where the final "expiration" is a property on the message, which is checked by an intermediary consumer.
Once all the messages were published on the new cluster, we were done and everything was still running.